TFLearn快速入门
以下是一个介绍TFLearn及其功能的基本指南。首先,重点介绍TFLearn用于快速构建和训练神经网络的高级API,然后展示TFLearn层、内置操作和辅助函数如何直接使Tensorflow的任何模型实现受益。
高级API使用
TFLearn引入了一个高级API,使神经网络的构建和训练变得快速而简单。该API直观且与Tensorflow完全兼容。
层
层是TFLearn的核心功能。虽然使用Tensorflow操作完全定义模型可能非常耗时且重复,但TFLearn带来了代表一组抽象操作的“层”,使构建神经网络更加方便。例如,一个卷积层将
- 创建并初始化权重和偏置变量
- 对输入张量应用卷积
- 在卷积之后添加一个激活函数
- 等等...
在Tensorflow中,编写这类操作可能会相当乏味
with tf.name_scope('conv1'):
W = tf.Variable(tf.random_normal([5, 5, 1, 32]), dtype=tf.float32, name='Weights')
b = tf.Variable(tf.random_normal([32]), dtype=tf.float32, name='biases')
x = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
x = tf.add_bias(x, b)
x = tf.nn.relu(x)
而在TFLearn中,只需一行代码即可完成
tflearn.conv_2d(x, 32, 5, activation='relu', name='conv1')
以下是当前可用层列表
| 文件 | 层 |
|---|---|
| 核心 | input_data、fully_connected、dropout、custom_layer、reshape、flatten、activation、single_unit、highway、one_hot_encoding、time_distributed |
| 卷积 | conv_2d、conv_2d_transpose、max_pool_2d、avg_pool_2d、upsample_2d、conv_1d、max_pool_1d、avg_pool_1d、residual_block、residual_bottleneck、conv_3d、max_pool_3d、avg_pool_3d、highway_conv_1d、highway_conv_2d、global_avg_pool、global_max_pool |
| 循环 | simple_rnn、lstm、gru、bidirectionnal_rnn、dynamic_rnn |
| 嵌入 | 嵌入 |
| 归一化 | batch_normalization、local_response_normalization、l2_normalize |
| 合并 | merge、merge_outputs |
| 估计器 | 回归 |
内置操作
除了层概念之外,TFLearn还提供了许多不同的操作,可在构建神经网络时使用。这些操作首先意味着是上述“层”参数的一部分,但为了方便起见,它们也可以独立用于任何其他Tensorflow图中。在实践中,只需提供操作名称作为参数就足够了(例如,conv_2d的activation='relu'或regularizer='L2'),但也可以提供一个函数以进行进一步的自定义。
| 文件 | 操作 |
|---|---|
| 激活函数 | linear、tanh、sigmoid、softmax、softplus、softsign、relu、relu6、leaky_relu、prelu、elu |
| 目标函数 | softmax_categorical_crossentropy、categorical_crossentropy、binary_crossentropy、mean_square、hinge_loss、roc_auc_score、weak_cross_entropy_2d |
| 优化器 | SGD、RMSProp、Adam、Momentum、AdaGrad、Ftrl、AdaDelta |
| 指标 | Accuracy、Top_k、R2 |
| 初始化器 | zeros、uniform、uniform_scaling、normal、truncated_normal、xavier、variance_scaling |
| 损失函数 | l1、l2 |
以下是一些快速示例
# Activation and Regularization inside a layer:
fc2 = tflearn.fully_connected(fc1, 32, activation='tanh', regularizer='L2')
# Equivalent to:
fc2 = tflearn.fully_connected(fc1, 32)
tflearn.add_weights_regularization(fc2, loss='L2')
fc2 = tflearn.tanh(fc2)
# Optimizer, Objective and Metric:
reg = tflearn.regression(fc4, optimizer='rmsprop', metric='accuracy', loss='categorical_crossentropy')
# Ops can also be defined outside, for deeper customization:
momentum = tflearn.optimizers.Momentum(learning_rate=0.1, weight_decay=0.96, decay_step=200)
top5 = tflearn.metrics.Top_k(k=5)
reg = tflearn.regression(fc4, optimizer=momentum, metric=top5, loss='categorical_crossentropy')
训练、评估和预测
训练函数是TFLearn的另一个核心功能。在Tensorflow中,没有用于训练网络的预构建API,因此TFLearn集成了一组函数,可以轻松处理任何神经网络训练,无论输入、输出和优化器的数量如何。
使用TFlearn层时,许多参数已经自动管理,因此使用DNN模型类训练模型非常容易
network = ... (some layers) ...
network = regression(network, optimizer='sgd', loss='categorical_crossentropy')
model = DNN(network)
model.fit(X, Y)
它也可以直接用于预测或评估
network = ...
model = DNN(network)
model.load('model.tflearn')
model.predict(X)
可视化
虽然编写Tensorflow模型并添加tensorboard摘要不太实用,但TFLearn能够自动管理许多有用的日志。目前,TFLearn支持一个详细级别来自动管理摘要
- 0:损失和指标(最佳速度)。
- 1:损失、指标和梯度。
- 2:损失、指标、梯度和权重。
- 3:损失、指标、梯度、权重、激活和稀疏性(最佳可视化)。
使用DNN模型类,只需指定verbose参数
model = DNN(network, tensorboard_verbose=3)
然后,可以运行Tensorboard来可视化网络和性能
$ tensorboard --logdir='/tmp/tflearn_logs'
图
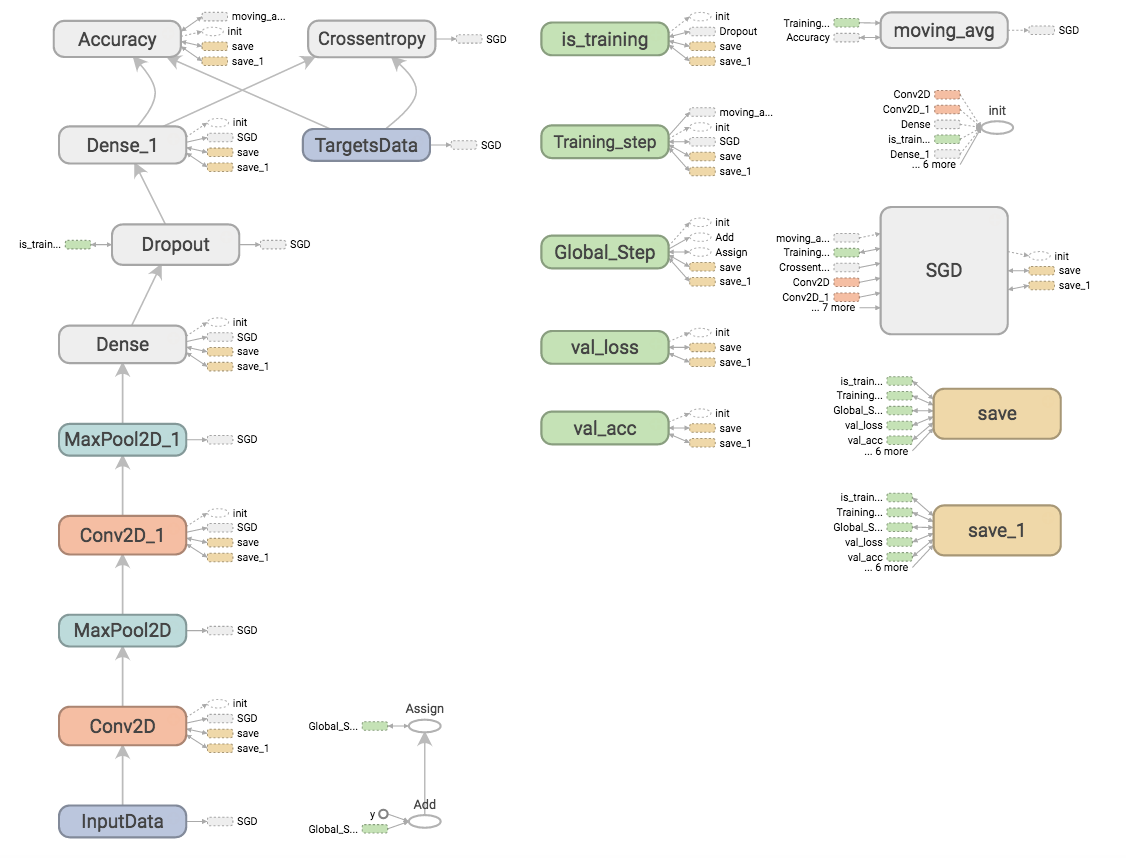
损失和准确率(多次运行)
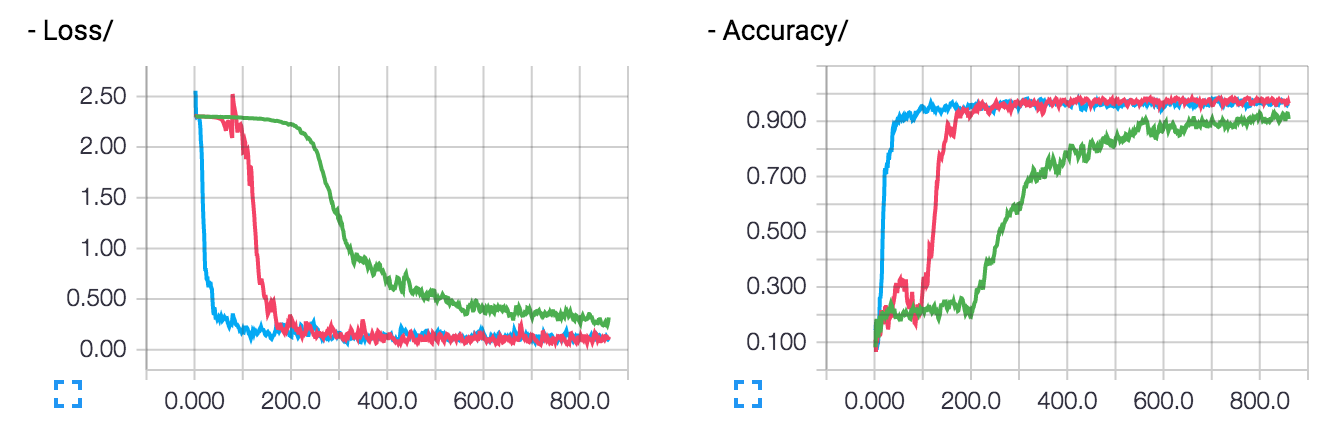
层
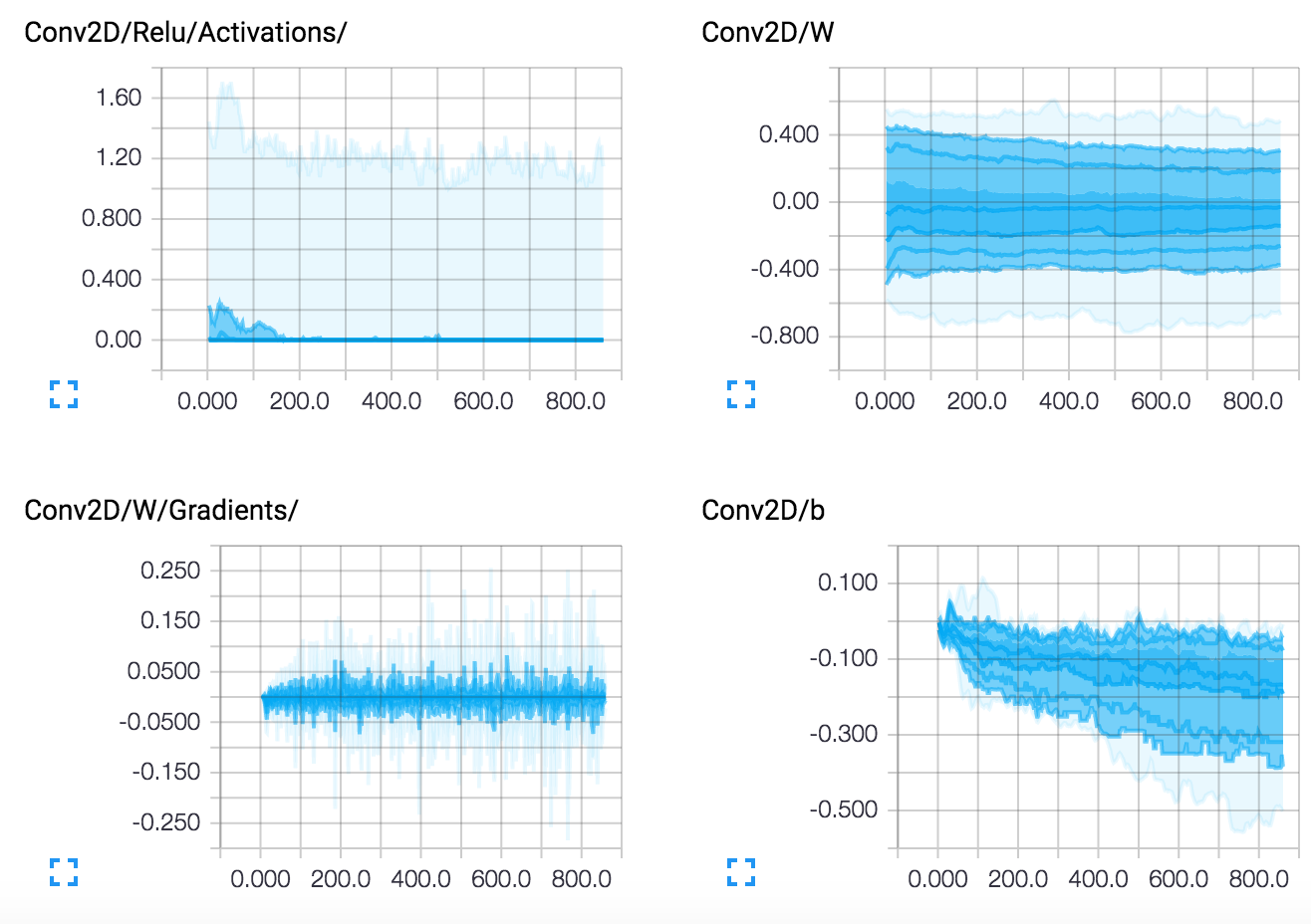
权重持久化
要保存或恢复模型,只需调用DNN模型类的“save”或“load”方法即可。
# Save a model
model.save('my_model.tflearn')
# Load a model
model.load('my_model.tflearn')
检索层变量可以使用层名称完成,也可以直接使用“W”或“b”属性完成,这些属性被增强到层的返回张量。
# Let's create a layer
fc1 = fully_connected(input_layer, 64, name="fc_layer_1")
# Using Tensor attributes (Layer will supercharge the returned Tensor with weights attributes)
fc1_weights_var = fc1.W
fc1_biases_var = fc1.b
# Using Tensor name
fc1_vars = tflearn.get_layer_variables_by_name("fc_layer_1")
fc1_weights_var = fc1_vars[0]
fc1_biases_var = fc1_vars[1]
要获取或设置这些变量的值,TFLearn模型类实现了get_weights和set_weights方法
input_data = tflearn.input_data(shape=[None, 784])
fc1 = tflearn.fully_connected(input_data, 64)
fc2 = tflearn.fully_connected(fc1, 10, activation='softmax')
net = tflearn.regression(fc2)
model = DNN(net)
# Get weights values of fc2
model.get_weights(fc2.W)
# Assign new random weights to fc2
model.set_weights(fc2.W, numpy.random.rand(64, 10))
请注意,您也可以直接使用TensorFlow的eval或assign操作来获取或设置这些变量的值。
- 有关示例,请参阅:weights_persistence.py。
微调
在许多情况下,在新任务上微调预训练模型可能很有用。因此,在TFLearn中定义模型时,您可以指定要恢复或不恢复哪些层的权重(加载预训练模型时)。这可以通过层函数的“restore”参数来处理(仅适用于具有权重的层)。
# Weights will be restored by default.
fc_layer = tflearn.fully_connected(input_layer, 32)
# Weights will not be restored, if specified so.
fc_layer = tflearn.fully_connected(input_layer, 32, restore='False')
所有不需要恢复的权重都将添加到tf.GraphKeys.EXCL_RESTORE_VARS集合中,并且在加载预训练模型时,将简单地忽略这些变量的恢复。以下示例展示了如何通过恢复除最后一个全连接层之外的所有权重来在新任务上微调网络,然后在新数据集上训练新模型
- 微调示例:finetuning.py。
数据管理
TFLearn支持numpy数组数据。此外,它还支持HDF5来处理大型数据集。HDF5是一种用于存储和管理数据的数据模型、库和文件格式。它支持无限多种数据类型,并且专为灵活高效的I/O以及大容量和复杂数据而设计(更多信息)。TFLearn可以直接使用HDF5格式的数据
# Load hdf5 dataset
h5f = h5py.File('data.h5', 'r')
X, Y = h5f['MyLargeData']
... define network ...
# Use HDF5 data model to train model
model = DNN(network)
model.fit(X, Y)
有关示例,请参阅:hdf5.py。
数据预处理和数据增强
在训练模型时执行数据预处理和数据增强是很常见的,因此TFLearn提供了包装器来轻松处理它。另请注意,TFLearn数据流的设计采用了计算流水线,以便加快训练速度(通过在CPU上预处理数据,同时GPU执行模型训练)。
# Real-time image preprocessing
img_prep = tflearn.ImagePreprocessing()
# Zero Center (With mean computed over the whole dataset)
img_prep.add_featurewise_zero_center()
# STD Normalization (With std computed over the whole dataset)
img_prep.add_featurewise_stdnorm()
# Real-time data augmentation
img_aug = tflearn.ImageAugmentation()
# Random flip an image
img_aug.add_random_flip_leftright()
# Add these methods into an 'input_data' layer
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
作用域和权重共享
所有层都构建在“variable_op_scope”之上,这使得在多个层之间共享变量变得容易,并使TFLearn适用于分布式训练。所有具有内部变量的层都支持一个“scope”参数,用于将变量放置在该参数下;具有相同作用域名称的层将共享相同的权重。
# Define a model builder
def my_model(x):
x = tflearn.fully_connected(x, 32, scope='fc1')
x = tflearn.fully_connected(x, 32, scope='fc2')
x = tflearn.fully_connected(x, 2, scope='out')
# 2 different computation graphs but sharing the same weights
with tf.device('/gpu:0'):
# Force all Variables to reside on the CPU.
with tf.arg_scope([tflearn.variables.variable], device='/cpu:0'):
model1 = my_model(placeholder_X)
# Reuse Variables for the next model
tf.get_variable_scope().reuse_variables()
with tf.device('/gpu:1'):
with tf.arg_scope([tflearn.variables.variable], device='/cpu:0'):
model2 = my_model(placeholder_X)
# Model can now be trained by multiple GPUs (see gradient averaging)
...
图初始化
在训练时限制资源或分配更多或更少的GPU RAM内存可能很有用。为此,可以使用图初始化器在运行之前配置图
tflearn.init_graph(set_seed=8888, num_cores=16, gpu_memory_fraction=0.5)
- 请参阅:config。
扩展Tensorflow
TFLearn是一个非常灵活的库,旨在让您独立使用其任何组件。可以使用Tensorflow操作和TFLearn内置层和操作的任意组合来简洁地构建模型。以下说明将向您展示使用TFLearn扩展Tensorflow的基础知识。
层
任何层都可以与来自Tensorflow的任何其他张量一起使用,这意味着您可以直接在您自己的Tensorflow图中使用TFLearn包装器。
# Some operations using Tensorflow.
X = tf.placeholder(shape=(None, 784), dtype=tf.float32)
net = tf.reshape(X, [-1, 28, 28, 1])
# Using TFLearn convolution layer.
net = tflearn.conv_2d(net, 32, 3, activation='relu')
# Using Tensorflow's max pooling op.
net = tf.nn.max_pool(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
...
- 有关示例,请参阅:layers.py。
内置操作
TFLearn内置操作使Tensorflow图的编写更快、更易读。因此,与层类似,内置操作与任何TensorFlow表达式完全兼容。以下代码示例展示了如何将它们与纯Tensorflow API一起使用。
- 请参阅:builtin_ops.py。
以下是可用操作列表,单击文件以获取更多详细信息
| 文件 | 操作 |
|---|---|
| 激活函数 | linear、tanh、sigmoid、softmax、softplus、softsign、relu、relu6、leaky_relu、prelu、elu |
| 目标函数 | softmax_categorical_crossentropy、categorical_crossentropy、binary_crossentropy、mean_square、hinge_loss、roc_auc_score、weak_cross_entropy_2d |
| 优化器 | SGD、RMSProp、Adam、Momentum、AdaGrad、Ftrl、AdaDelta |
| 指标 | Accuracy、Top_k、R2 |
| 初始化器 | zeros、uniform、uniform_scaling、normal、truncated_normal、xavier、variance_scaling |
| 损失函数 | l1、l2 |
注意:- 优化器设计为类而不是函数,有关在TFlearn模型之外的使用,请查看:optimizers。
训练器/评估器/预测器
如果您正在使用自己的Tensorflow模型,TFLearn还提供了一些“辅助”函数,可以训练任何Tensorflow图。通过引入实时监控、批处理采样、移动平均线、tensorboard日志、数据馈送等,可以使训练更加方便。它支持任意数量的输入、输出和优化操作。
TFLearn实现了一个TrainOp类来表示一个优化过程(即反向传播)。它的定义如下
trainop = TrainOp(net=my_network, loss=loss, metric=accuracy)
然后,所有TrainOp都可以馈送到Trainer类中,该类将处理整个训练过程,将所有TrainOp视为一个整体模型。
model = Trainer(trainops=trainop, tensorboard_dir='/tmp/tflearn')
model.fit(feed_dict={input_placeholder: X, target_placeholder: Y})
虽然大多数模型只有一个优化过程,但对于更复杂的模型来说,处理多个优化过程可能很有用。
model = Trainer(trainops=[trainop1, trainop2])
model.fit(feed_dict=[{in1: X1, label1: Y1}, {in2: X2, in3: X3, label2: Y2}])
-
要详细了解TrainOp和Trainer,请参阅:trainer。
-
有关示例,请参阅:trainer.py。
对于预测,TFLearn实现了一个Evaluator类,其工作方式与Trainer类似。它将任何网络作为参数,并返回预测值。
model = Evaluator(network)
model.predict(feed_dict={input_placeholder: X})
- 要详细了解Evaluator类,请参阅:evaluator。
为了处理在训练和测试阶段具有不同行为的层的网络(例如dropout和batch normalization),Trainer类使用一个布尔变量('is_training')来指定网络是用于训练还是测试/预测。此变量存储在tf.GraphKeys.IS_TRAINING集合下,作为其第一个(也是唯一一个)元素。因此,在定义此类层时,应将此变量用作操作条件
# Example for Dropout:
x = ...
def apply_dropout(): # Function to apply when training mode ON.
return tf.nn.dropout(x, keep_prob)
is_training = tflearn.get_training_mode() # Retrieve is_training variable.
tf.cond(is_training, apply_dropout, lambda: x) # Only apply dropout at training time.
为了方便起见,TFLearn实现了一些函数来检索该变量或更改其值
# Set training mode ON (set is_training var to True)
tflearn.is_training(True)
# Set training mode OFF (set is_training var to False)
tflearn.is_training(False)
- 请参阅:training config。
训练回调
在训练周期中,TFLearn使您能够通过Callback接口提供的一组函数来跟踪训练指标并与之交互。为了简化指标检索,每个回调方法都接收一个TrainingState,它跟踪状态(例如:当前时期、步骤、批处理迭代)和指标(例如:当前验证准确率、全局准确率等)。
与训练周期相关的回调方法:- on_train_begin(training_state) - on_epoch_begin(training_state) - on_batch_begin(training_state) - on_sub_batch_begin(training_state) - on_sub_batch_end(training_state, train_index) - on_batch_end(training_state, snapshot) - on_epoch_end(training_state) - on_train_end(training_state)
如何使用它
假设您有一个监控器,用于跟踪所有训练作业,并且您需要向其发送指标。您可以通过创建一个自定义回调函数轻松地做到这一点,该函数将获取数据并将其发送到远程监控器。我们需要创建一个 CustomCallback,并在 on_epoch_end 中添加您的逻辑,该逻辑将在每个 epoch 结束时被调用。
这将为您提供如下内容
class MonitorCallback(tflearn.callbacks.Callback):
def __init__(self, api):
self.my_monitor_api = api
def on_epoch_end(self, training_state):
self.my_monitor_api.send({
accuracy: training_state.global_acc,
loss: training_state.global_loss,
})
然后,您只需要在 model.fit 调用中添加它即可
monitorCallback = MonitorCallback(api) # "api" is your API class
model = ...
model.fit(..., callbacks=monitorCallback)
callbacks 参数可以接受一个 Callback 或一个 list 的回调函数。就是这样,您的自定义回调函数将在每个 epoch 结束时自动调用。
变量
TFLearn 定义了一组函数,供用户快速定义变量。
在 Tensorflow 中,变量创建需要预定义的值或初始化器,以及显式的设备放置,而 TFLearn 简化了变量定义
import tflearn.variables as vs
my_var = vs.variable('W',
shape=[784, 128],
initializer='truncated_normal',
regularizer='L2',
device='/gpu:0')
- 例如,请参见:variables.py。
摘要
使用 Trainer 类时,管理摘要也非常容易。它只是额外要求将要监控的激活存储到 tf.GraphKeys.ACTIVATIONS 集合中。
然后,只需指定一个详细级别来控制可视化深度
model = Trainer(network, loss=loss, metric=acc, tensorboard_verbose=3)
除了 Trainer 自我管理的摘要选项外,您还可以直接使用 TFLearn 操作快速将摘要添加到当前的 Tensorflow 图中。
import tflearn.helpers.summarizer as s
s.summarize_variables(train_vars=[...]) # Summarize all given variables' weights (All trainable variables if None).
s.summarize_activations(activations=[...]) # Summarize all given activations
s.summarize_gradients(grads=[...]) # Summarize all given variables' gradient (All trainable variables if None).
s.summarize(value, type) # Summarize anything.
上面的每个函数都接受一个集合作为参数,并将返回该集合上的合并摘要(默认名称:'tflearn_summ')。因此,您只需要运行最后一个摘要器即可获取整个摘要操作集合,该集合已经合并。
s.summarize_variables(collection='my_summaries')
s.Summarize_gradients(collection='my_summaries')
summary_op = s.summarize_activations(collection='my_summaries')
# summary_op is a the merged op of previously define weights, gradients and activations summary ops.
- 例如,请参见:summaries.py。
正则化器
可以使用 TFLearn 正则化器完成向模型添加正则化。它目前支持权重和激活正则化。可用的正则化损失可以在此处找到。所有正则化损失都存储在 tf.GraphKeys.REGULARIZATION_LOSSES 集合中。
# Add L2 regularization to a variable
W = tf.Variable(tf.random_normal([784, 256]), name="W")
tflearn.add_weight_regularizer(W, 'L2', weight_decay=0.001)
预处理
除了张量操作之外,对输入数据执行一些预处理可能也很有用。因此,TFLearn 有一组预处理函数,使数据操作更加方便(例如序列填充、分类标签、同步混洗、图像处理等)。
- 有关更多详细信息,请参见:data_utils。
进一步学习
有许多示例以及许多神经网络实现可供您更深入地练习 TFLearn
- 请参见:示例。